Pandalism
Felix DMR's Blog
Programming, Electronics, Autonomous Vehicles and other interests!
Copyright © 2023 Pandalism
19 September 2020
I will always admit I suffer from digital compulsive hoarding, practically saving everything digital I interact with. If I watch it on Netflix or Amazon, I’ll go download it right after, even if I never watch it again.
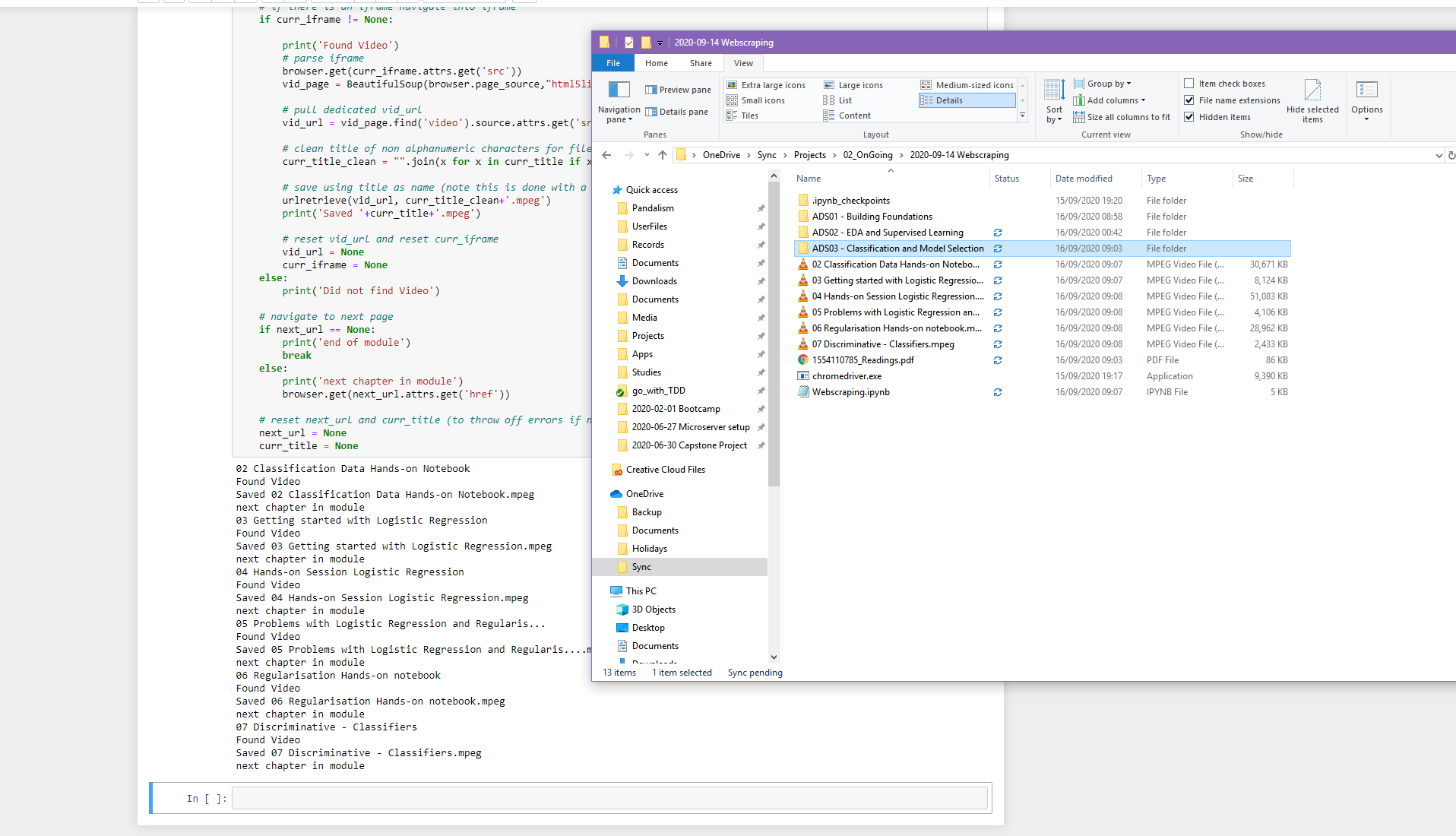
In a similar fashion I wanted to save all the videos from the bootcamp I just did, to safeguard in case I need to ever refer to them in the future (not to share, promise!). Considering I hadn’t had much webscraping practice before I thought it was good mini-project.
Sifting through the source code
So using the trusty developer mode in Chrome makes this a walk in the park. It’s how I’d usually just download the undownloadable, but automating ~1000’s of clicks keeps the RSI-monster away.
Poking around, it appeared the anchor links for the ‘next’ arrow were conveniently tagged next, and the video was nested within the only <iframe> in the whole page. If there was no video, then no <iframe>.
Within said <iframe> the page had the embedded video tag, and although not ‘right-clickable’, it had an unencoded source URL and zero javascript magic trying to obfuscate it. Even more conveniently, that very source URL integrated the key to authorize it so it even downloaded when loaded in incognito mode (don’t need cookies to download).
So the logic was simple:
- Get the chapter name
- Get the next chapter url
- Load the iframe sourcecode, and from that the video url source
- Download video
- Go to the next chapter and repeat until no more ‘next’ button (so the end of the module).
Manually intervening between the modules was desired, to make sure it was downloading them correctly and file the videos away in the right folders, but that could have also been automated…
Tools and conda setup
I use Conda for all my python work and it just makes managing the environment so easy. To save space, I usually delete my environments after done, but always save the package-lists with any project, makes spinning them back up a breeze! As such I’ll include them with any code I upload.
To play around with this I just installed beautifulsoup and selenium, two pretty well known libraries for parsing html output and browser-based testing.
conda create --name webscrape-test
conda activate webscrape-test
conda install beautifulsoup4
conda install html5lib
conda install selenium
conda install jupyter
Separately you’ll also have to download the ‘chromedriver’ which allows selenium to interact with chrome. Just select the version you need and drop it off in your working directory (no need for putting it on PATH). If you want to use something other than Chrome, Selenium’s docs will point you in the right direction.
Jupyter notebook
I think the notebook is broadly self explanatory (might have over done it with the comments), but the basic idea is to trigger Selenium to open the talentLMS website, login, then navigate to the first page of the module you want to download. If the ‘Next’ arrow is on the page, let the full loop run and the logic should do the rest.
Only two caveats I fell upon: One was that Selenium and chrome combination did not allow to change the filename when saving the video, but since the video URL had the authorization to download, a simple urllib request solves that issue. Secondly, silly characters broke the filename once or twice, but a quick string check fixed that.
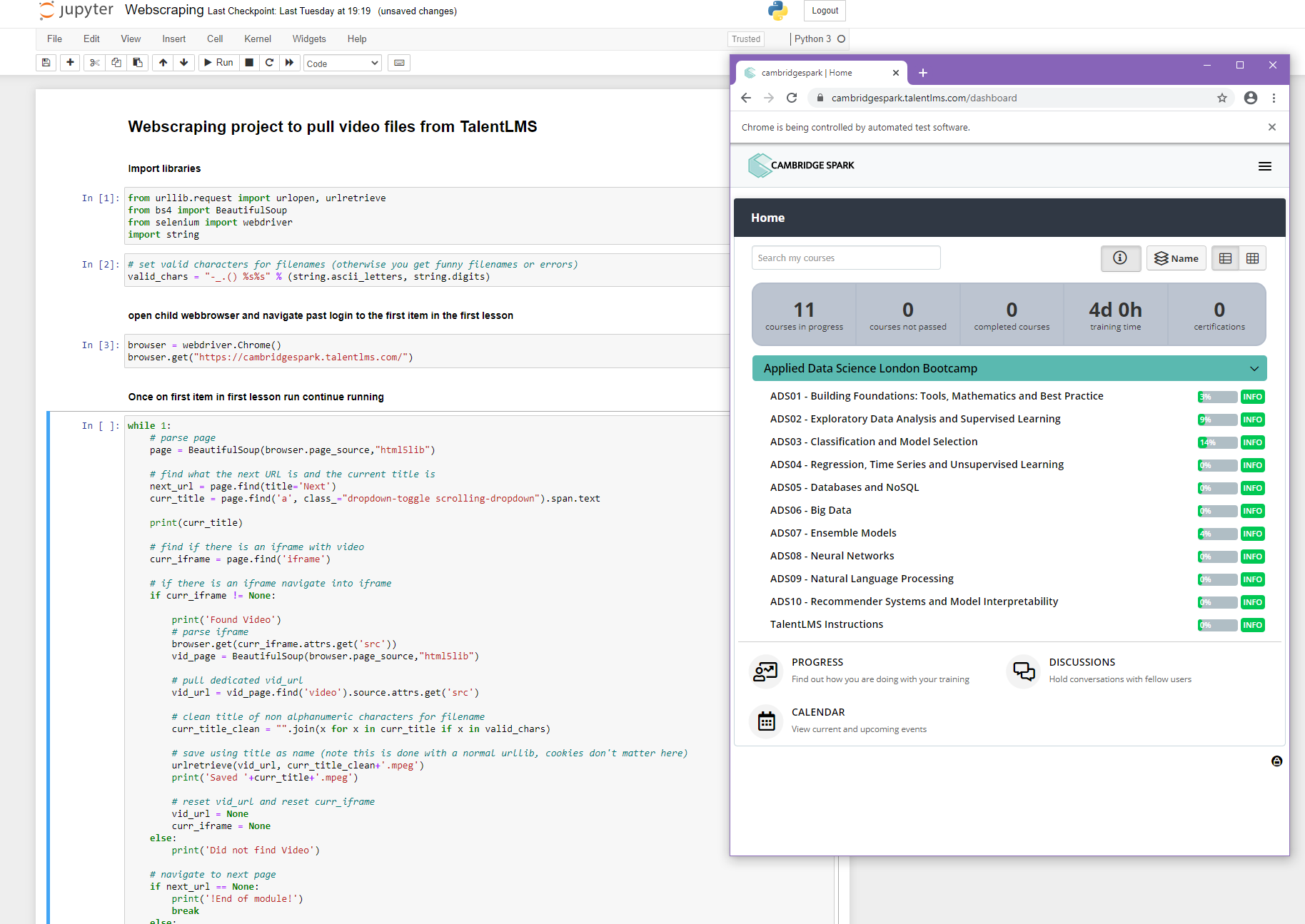 On intial load, login and navigate to the modules
On intial load, login and navigate to the modules
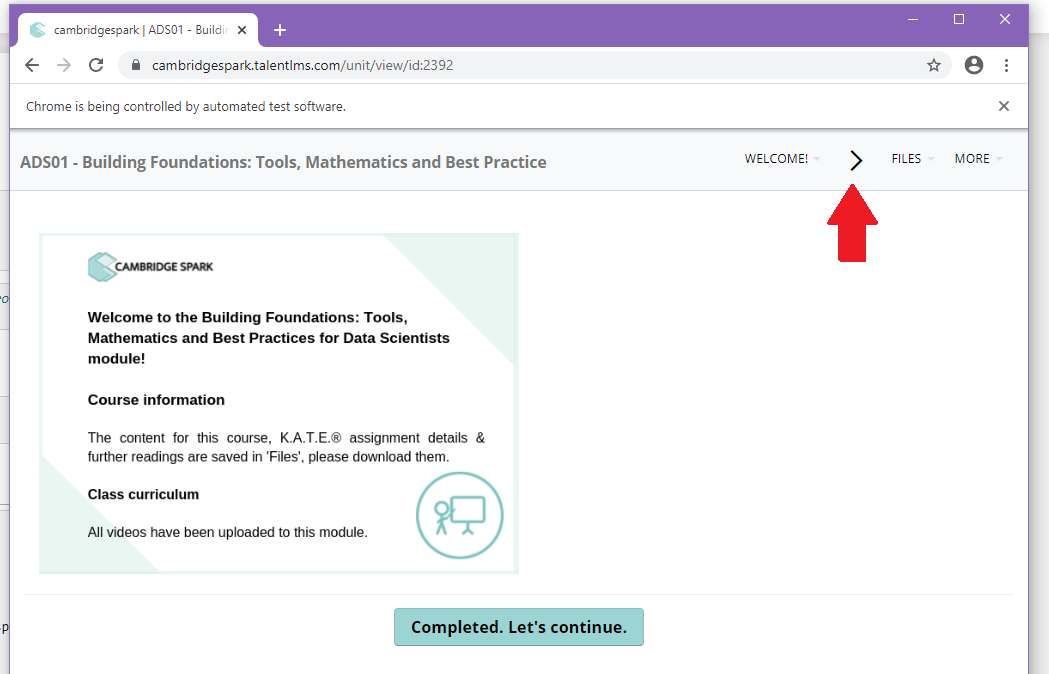 If it shows the arrow it's in the right level
If it shows the arrow it's in the right level
Conclusion
That was actually… a lot easier than expected. Took longer to write this silly post than to make it loop smoothly. Its good to know a little about the document object model, web development practices and usual ways that websites will obfuscate their data against scraping, but in this case this was so simple anyone could have done it in under 30mins with google’s help.
There is the question of whether Selenium is really used very much here, I could have nicked a cookie from a browser and just used all urllib functions. However that already was more effort than opening a page and logging in once.
Nonetheless, its good practice, and I satiate my hoarding tendencies. The jupyter notebook + conda setup is above in case anyone wants to try it/modify it. Please keep in mind to use it only for personal use and education…so don’t share the resultant data out to the world as in the end these companies work hard, and have to pay, to create tutorial materials to host on talentLMS.
Credit and links
-realpython.com on webscraping, makes this really a trivial excersise
Copyright © 2023 Pandalism